Learning Playwright With Another Automation Project
TL;DR
I built a game autoplayer using Python with Playwright as the automation library of choice, and beautifulsoup as its sidekick! You can take a look here.
Learning Playwright For a Practical Use Case
It’s been a while. There’s a lot that I have learned and there is a lot that I want to learn, but there was something from my past that I just had to revisit and get done before I could move forward. If you guessed “UI autoplayer for second Neoquest game”, then you guessed right.
Call it a quirk or an obsession, but this is something that I knew I wanted to do for a while. I like to think that it was for the people, regardless of how many people that title really consists of. Honestly, I’m aware that the intersection of Neopets players and people who browse Github for Neopets programs is basically non-existent. However, I also do know for a fact that some small number of people in the past have used these tools (even if they don’t work 100%!), and that makes me happy.
I don’t plan to do any more automation for Neopets, but I like to think that my job is mostly done after this project anyway. Neoquest and Neoquest II are massive games that take normal people weeks of following a guide to complete. Imagine having to play them three times on successively harder difficulties. I wanted to create a program so that people could collect the trophies without doing that. What was fun as a kid is no longer so much fun when a Neopets player potentially has kids of their own by now.
So I’ve yapped a lot about the project now, but what is it exactly again? I know it’s not going to sound entirely novel. It’s an autoplayer for the other much larger and more complex Neopets PHTML game, Neoquest II, but this time powered by Playwright instead of Selenium. The first question here would be, “Why Playwright if you already know Selenium?”, and my answer is this. When I learned Selenium, I believe it was still the de facto browser automation tool. Alternatives like Puppeteer and Cypress existed, but I’m fairly certain that Selenium was still by far the most popular library at that point. And to its credit, Selenium did its job well with some pain points along the way. But then Playwright came along and took over seemingly overnight, and I wanted to know what the deal was. Why did it take the testing community by storm?
Playwright to me has mostly been a joy to work with. It’s relatively simple to use out of the box, is said to be faster than Selenium, has auto-waiting, supports both synchronous and asynchronous APIs, and more. I’m sure I’ve just skimmed the surface. People often have a lot of choice words about Microsoft when it comes to their operating systems, and I myself am not usually one to praise the big companies, but Playwright really lived up to my expectations.
The second question might be, “Why a browser-based autoplayer when web requests would do it more reliably?” This is a something I’ve thought about for a long time. Why go through the trouble of manipulating a web UI when web requests can deliver you the results directly? And really, my choice isn’t related to that at all. Rather, my concern was how websites are making automation with requests increasingly difficult because of authentication. Back in the simpler days, it was cookie-based authentication. Provide your login details once, and get a cookie that you don’t need to worry about for a while. On the other hand, tokens seem to be set to expire much sooner, plus detecting token expiration and then also hitting the correct endpoint to get a new one (if you can even find it!) is no easy task. The majority of the time, it is simply easier to have a browser itself handle these aspects.
What It Does
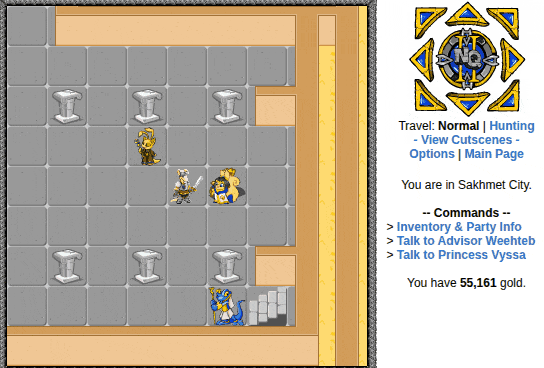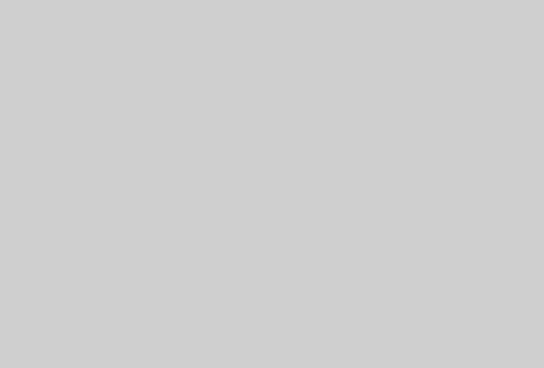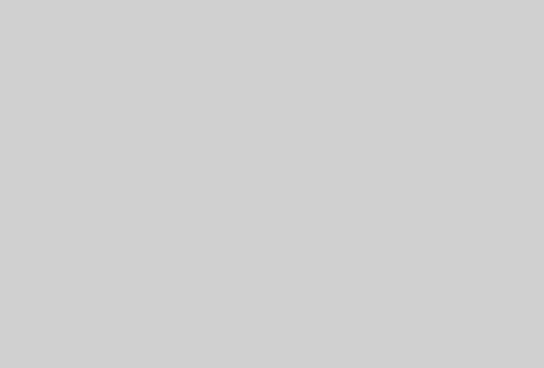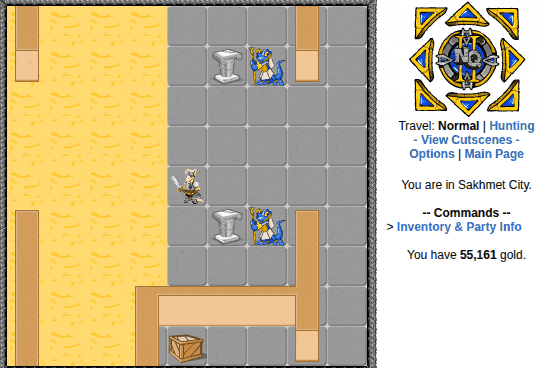
I’m not exactly going to brag about how it looks. It runs a headed browser but has a terminal interface with some menu options. You select one of several options, and the autoplayer will perform the task, handling all interactions and battling as needed. Here’s a quick demonstration of overworld movement and battling:
 |
|---|
| Page loading was a bit slow, but you get the idea |
 |
|---|
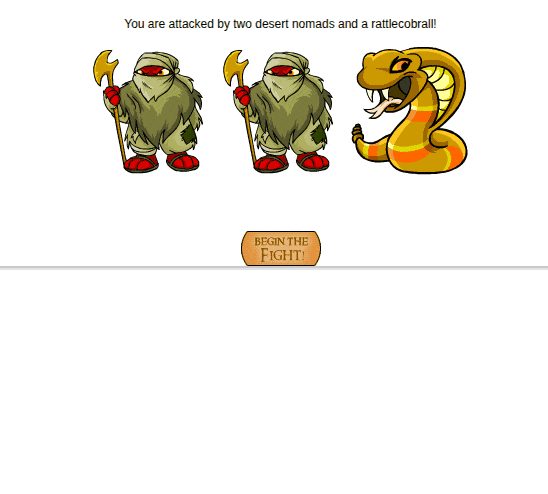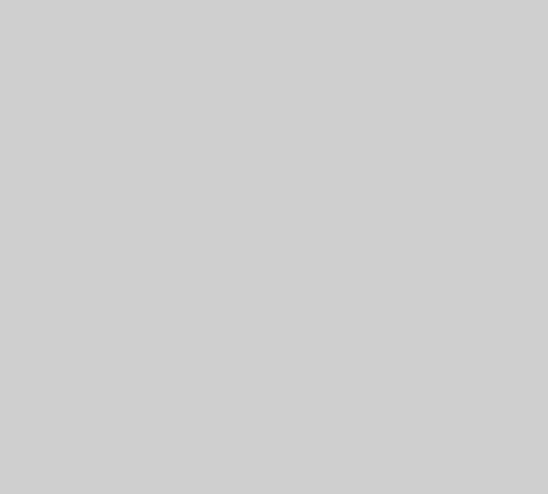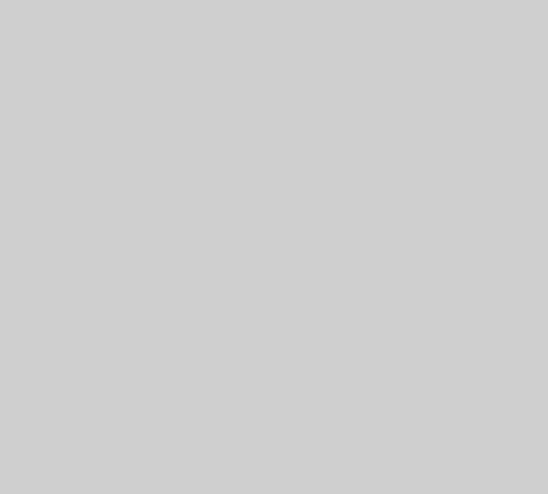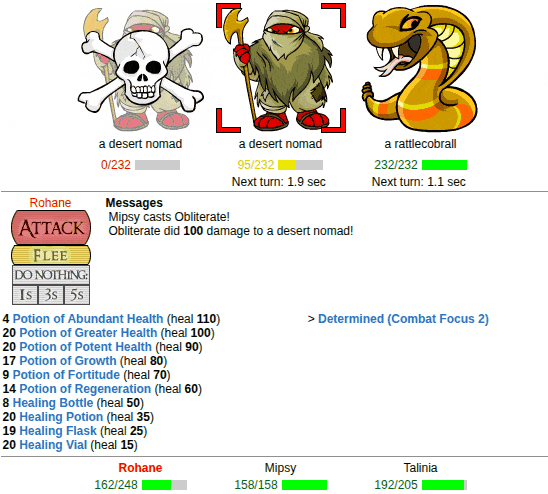
| Battling is fully automated too! |
There’s a bit more to it like interacting with spending skill points and talking to NPCs, but the other large part of this project after getting the core functionality down was mapping out the whole game and squashing bugs during testing. That took a very significant amount of time compared to building up the framework. Plenty of method rewrites and edge case handling that were very difficult to test on because of their rarity.
Issues and Learnings
Timing issues are the bane of web automation folks, right? Well, actually not in this case. Playwright handles the waiting on locators for me, but that doesn’t mean there are no issues. By far the biggest one was failing page loads. When you send a web request, you get a status code indicating whether that request completely successfully or not. When you are clicking buttons, there is no such certainty. When the page fails to load, your request may still have gone through. The problem is identifying some page change that indicates whether it did or not. The issue was that the only indicator was the overworld map, and the 9x9(?) grid of images that made up the map were not necessarily unique after navigation. We had to get creative and extract the (broken!) coordinate attributes from the map elements and determine whether they changed or not.
Now let me expand just a little. When encountering broken HTML, beautifulsoup is generally still quite good at parsing it, but not in this case. We instead had to take the webpage HTML itself and extract the text matching the coordinates with a regular expression, and then take those coordinates and compare them. It wasn’t pretty, but I can’t think of another way to do it really. I did entertain the idea of just hashing the entire navigation map HTML and pray that it would be the same each time, but ultimately I decided that wasn’t the way to go.
We ran into more issues with requests succeeding after failed page loads, leading to unexpected pages appearing where we really expected another page instead. These were very tough to catch, and still they can probably be handled better. I simply wanted to handle them such that the program could recover from them.
Lastly, there is an uncommon but breaking bug caused by the Neopets server duplicating a requested action. This I have no control over, nor do I even have a method to detect and recover from it. I hope it doesn’t keep me awake at night too much. To be fair, I wrote an entire section showing users where to backtrack to if the program failed them.
In the end, I think I did a pretty good job handling the edge cases. I’m sure there are some obscure scenarios that might not be accounted for, but I’m generally quite satisfied with the number of issues that can be recovered from.
Conclusion
I feel happy after getting this done. I know it’s not perfect, but I feel like I’ve done enough. It was good practice with the POM framework design, it was good for me to finish something that had been on my mind for so long, and I can finally leave the chapter of Neopets behind (unless someone raises an issue telling me that the program doesn’t work anymore haha). Onto bigger and better things.